MongoDB University에서 자바 개발자를 위한 MongoDB 강좌를 들었다. 시작한지 꽤 됐지만 바쁜 핑계로 아직도 끝내진 못했는데 정리 삼아 올려본다. 서너달에 한번씩 여러 강좌를 순환하므로 관심있다면 수강해보길 권한다.
MongoDB 개념
NoSQL 데이터베이스로서 JSON 형태의 데이터를 저장한다. SQL을 지원하지 않기 때문에 조인 개념이 없고 스키마는 유동적이다. 유동적이라는 말은 MongoDB에서 저장하는 데이터 단위는 "문서"인데 관계형 데이터베이스에서 행 단위의 레코드라고 할 수 있다. 하지만 문서의 속성은 DB 컬럼처럼 정형화된 것이 아니라 가변적이라 모든 문서의 형태는 다를 수 있다는 것이다.
다른 개념으로 말하자면 문서 지향 (Document Oriented) 데이터베이스다. 문서를 집합적으로 부르는 명칭은 "컬렉션"이다.(관계형 DB에서의 테이블에 대응되는 개념)
규모확장성 및 성능
^
| * memcached
| * Key-value store * MongoDB
|
|
|
| * RDBMS
+-------------------------------> 기능 깊이
- 확장성/성능 대비 기능에 대한 도표
RDBMS는 우수한 하드웨어를 확장해야만 실질적인 성능 향상이 있는데 MongoDB는 memcached보다는 기능이 많으면서 RDBMS보다는 성능이 우수한 것을 목표로 한다.
MongoDB는 1. 성능을 위해 조인 기능은 포기했고 2. 트랜잭션 없으나 문서가 계층화돼 있고 문서를 atomic하게 처리할 수 있으므로 트랜잭션과 유사한 효과가 있다. 여러 문서간에 걸친 트랜잭션을 지원하지는 않는다.
애플리케이션 개발 개요
본 강의에서는 블로그를 개발해보기로 한다. 다음은 개략적인 아키텍처다. (클릭하면 내가 열심히 다시 그린 그림 팝업!)
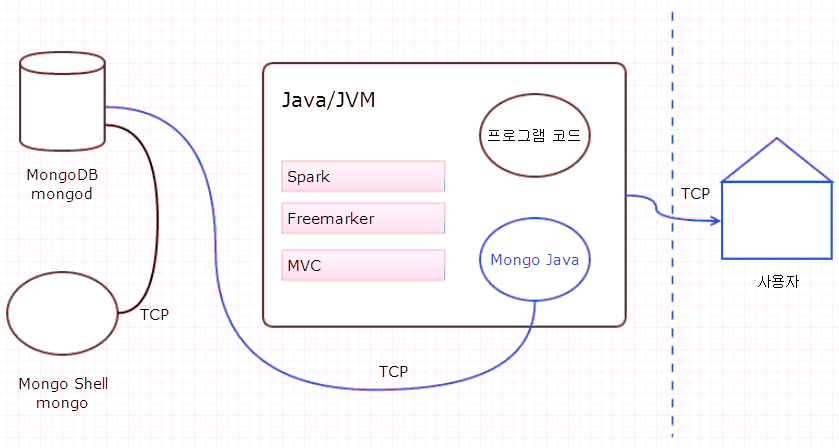
MongoDB 자바 드라이버를 통해 데이터를 처리하고 사용자에게 웹페이지를 보이는 방식이다. 웹 개발용 프레임웍으로는 Spark, Freemarker를 사용하기로 한다.
시스템 요구 사항 및 설치
- JDK 1.6 이나 1.7이 필요하다.
- MongoDB 사이트에서 다운로드한 다음 실행만 하면 간단히 설치된다.
- 설치 폴더에서 mongod.exe를 실행하면 명령 프롬프트로 데이터베이스 서버가 실행된다. 이제 mongo.exe 셸 프로그램으로 연결하거나 Mongo 자바 드라이버를 통해 프로그램적으로 연결해 사용할 수 있다.
Spark 프레임웍
간단한 웹프레임웍으로서 “라우트” 개념으로 웹요청 주소를 Java 클래스/메서드에 대응시킨다. 다음은 예제다.
public static void main(String[] args) {
Spark.get(new Route("/") {
@Override
public Object handle(final Request request,
final Response response) {
return "Hello World From Spark\n";
}
});
}Freemarker
템플리팅 엔진으로서 템플릿 파일 내용의 변수나 조건문, 루프 등을 데이터로 치환할 수 있다. 웹과는 무관하게 사용할 수 있는 엔진이다. 다음은 예제다.
public static void main(String[] args) {
Configuration configuration = new Configuration();
configuration.setClassForTemplateLoading(
HelloWorldFreemarkerStyle.class, "/");
try {
Template helloTemplate = configuration.getTemplate("hello.ftl"); // 템플릿 파일 로드
StringWriter writer = new StringWriter();
Map<String, Object> helloMap = new HashMap<String, Object>();
helloMap.put("name", "Freemarker");
helloTemplate.process(helloMap, writer);
System.out.println(writer);
} catch (Exception e) {
e.printStackTrace();
}
}다음은 hello.ftl 템플릿 파일이다.
<html>
<head>
<title>Welcome!</title>
</head>
<body>
<h1>Hello ${name}</h1>
</body>
</html>Spark + Freemarker + MongoDB
이제 세 가지를 혼합한 예제를 보자.
public static void main(String[] args) throws UnknownHostException {
final Configuration configuration = new Configuration();
configuration.setClassForTemplateLoading(
HelloWorldSparkFreemarkerStyle.class, "/");
MongoClient client = new MongoClient(new ServerAddress("localhost", 27017));
DB database = client.getDB("course");
final DBCollection collection = database.getCollection("hello");
Spark.get(new Route("/") {
@Override
public Object handle(final Request request,
final Response response) {
StringWriter writer = new StringWriter();
try {
Template helloTemplate = configuration.getTemplate("hello.ftl");
DBObject document = collection.findOne();
helloTemplate.process(document, writer);
} catch (Exception e) {
halt(500);
e.printStackTrace();
}
return writer;
}
});
}DBObject는 java.util.Map을 구현한 클래스라 Template.process 메서드에 그대로 전달할 수 있다.
개발하려는 블로그의 관계형 모델
일반적으로 블로그를 관계형 모델로 개발한다면 다음과 같은 형태가 될 것이다. 게시물 posts, 댓글 comments 등의 엔터티 테이블이 있고 그 사이를 연결해주는 관계 테이블 등이 있다.
posts comments tags
------ ----------- -------
post_id comment_id tag_id
author_id name name
title comment
post email
date
post_tags post_comments authors
----------- --------------- --------
post_id post_id author_id
tag_id comment_id username
password
Mongo 모델
MongoDB는 JSON 객체를 저장하므로 위의 관계 모델이 적용되지 않고 임의로 데이터를 저장할 수 있다. Posts라는 컬렉션을 만들 것인데 그 안에 작성자, 댓글 등을 모두 넣도록 설계할 수 있다. 이렇듯 스키마 설계시 컬렉션을 분리하느냐 마느냐가 중요한 선택 사항이다. To embed or not to embed, that is the question!
태그나 댓글을 Posts 컬렉션에 넣는 이유는 게시물을 액세스할 때 태그나 댓글도 거의 항상 액세스하기 때문이다.
한편 현실적으로는 16MB가 문서(document)의 한계기 때문에 예를 들어 댓글이 16MB가 넘을 것으로 예상된다면 분리해야 할 수도 있다.