요즘 Coursera에서 추천 시스템 입문(Introduction to Recommender Systems) 강의가 9월 3일에 개강하여 듣고 있다.
우선 이런 우수한 대학 과목을 온라인으로 무료 수강한다는 데 대해 대단히 감사하고 있다. 이 강의는 미국 미네소타 대학의 정규 과목을 옮겨 놓은 것으로 학부 학생도 온라인으로 똑같이 수강하는 과목이다. 미국에 가지 않고도 미국 대학의 정규 과목을 그대로 수강한다는 건 참 감격스러운 일이다. 물론 이미 몇 년 전부터 MIT 오픈코스웨어 등이 있었지만 수강생으로서 과제도 제출하고 시험도 볼 수 있게 정말 학생처럼 그것도 무료로 관리 받는 것으로서는 또 한번 새로운 변화라 할 수 있다.
추천 시스템은 쇼핑몰 같은 웹사이트에서 상품 정보를 볼 때 관련 상품 정보 등을 제공하는 서브시스템을 말한다. 책이나 영화 사이트에서 개인의 취향이나 과거 구매 패턴에 따라 추천하는 경우를 일반적으로 접해봤을 것이다.
한 학기 동안 비디오 보는 데 3시간, 필기 숙제 및 프로그래밍 숙제가 1주일에 10시간은 될 예정이라 만만치 않은 투자다. 또 이것 말고도 수강 중인 게 하나 더 있어 부담은 더 하다.
이러한 투자가 헛되지 않도록 강의 내용도 정리하고 숙제도 잘 해볼 예정이다. 아래는 제1강 추천 시스템 입문(Introduction to Recommender Systems)을 내가 요약한 내용이다. 영어 표현을 그대로 쓰고 싶진 않았지만 의미 전달에 있어 어쩔 수 없는 면이 있었다. 강의 개요 및 진행 방식에 대한 요약은 넣지 않았다.
추천 시스템의 개념 체계(taxonomy)
추천에 있어서 다음 영역(dimension)을 고려해야 한다.
추천의 도메인
- 상거래 등의 컨텐트 - 뉴스, 정보, 상품, 벤더, 짝연결, 시퀀스(음악 재생 목록 등)
- 특정 관심 속성 - 신상품, 과거 것을 재추천(식료, 음악)
구글도 어떤 면에서는 검색 결과를 추천하는 것이라고 볼 수 있다.
추천의 목적
- 추천 자체 - 판매, 정보
- 사용자, 고객에 대한 교육 - 프로그램 사용 방법 교육을 위한 기능 추천
- 제품, 컨텐트에 대한 사용자, 고객 커뮤니티 형성
추천 컨텍스트
- 추천 시점에서 사용자의 행위 - 쇼핑? 음악? 사람들과 놀기?
- 컨텍스트에 따라 추천이 어떻게 제한되는가
누구의 의견인가?
- 전문가? - wine.com의 성공은 전문가인 "피터"의 의견이 주효했다
- 대중? - phoaks.com는 유스넷 의견 교환 사이트
기타
- 개인화 - 일반/비개인화, 인구학적 타겟 그룹(성인 남성 등), 개인 맞춤
- 프라이버시
- 신뢰성 - 상품이 떨어졌다든가 해서 추천하지 않는 경우가 있다
- 인터페이스 - 출력 유형(예측, 추천, 필터링), 입력 유형(직접 입력, 묵시적 입력)
- 추천 앨거리듬 (앨거리듬의 자세한 내용은 향후 계속)
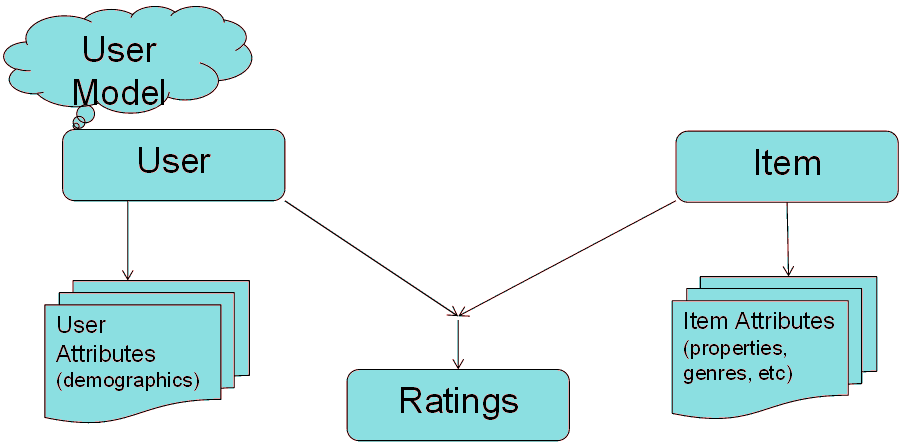
추천 시스템의 기본 모형
- 사용자 - 사용자 및 사용자 속성(예: 나이 등 인구학적 속성), 사용자 모델(예: 좋아하는 영화 장르, 책 종류)
- 추천 대상 항목 - 항목 및 항목 속성(영화 장르, 책 종류, 호텔)
- 평가(ratings) - 사용자가 항목을 좋아하는지, 평점은 얼마인지 등
- 커뮤니티
추천 시스템 유형
- 비개인화된 요약 통계 - 베스트셀러, 인기도, 트렌드
- 컨텐트 기반 필터링 - 사용자 평가와 항목 속성의 조합, 또는 지식 기반으로 항목 속성에 따른 구분(개인화된 뉴스 피드 등). 사용자가 원하는 컨텐트의 속성(액션, SF 등)에 따라 컨텐트의 속성이 일치하는 것을 찾아 제공하는 기본 방식
- 개인화된 협업 필터링 - 다른 사람의 예상, 추천을 활용. 모든 사람들의 모든 취향을 파악하는 매트릭스(조견표)가 있다면 그 중 알지 못하는 취향을 채워넣어야 할 것이다.
- 사용자-사용자 - 취향이 비슷한 다른 사람들의 정보를 활용해 채워넣을(추천) 수 있다
- 항목-항목 - 속성이 비슷한 다른 항목을 통해 추측해 채워넣을(추천) 수 있다
- 각 접근법의 장점을 알기 위해 평가가 아주 중요하다
- 다른 접근법으로 인터랙티브 추천(비평가 기반, 대화식 기반), 여러 기법의 조합이 있다
아마존(amazon.com) 사례로 본 추천 시스템 분석
분석 프레임웍 - 분석 영역(dimensions)으로는 도메인, 목적, 추천 컨텍스트, 누구의 의견인가, 개인화 수준, 프라이버시 및 신뢰성, 인터페이스, 추천 앨거리듬이 있다.
아마존에서 페이지를 들여다보면 다른 사람들이 지금 보는 것, 다른 사람들이 본 것, 함께 살 것, 함께 산 것, 관련 상품 추천 등 몇 가지 추천을 찾을 수 있다.
| 다른 사람들이 지금 보는 것 | 관련 상품 | 메일 추천 | |
|---|---|---|---|
| 도메인 | 상품 | ← | ← |
| 목적 | 판매 | ← | ← |
| 추천 컨텍스트 | 시간 | 상품 연관성 | |
| 누구의 의견인가 | 다른 고객(일반인) | 상품을 봤거나 산 사람 | 알 수 없음 |
| 개인화 정도 | 없음 | 순간적 | 영속적(과거 구매, 평가, 브라우징 기반) |
| 프라이버시 및 신뢰성 | 저위험 | ← | |
| 인터페이스 | 단순 상품 설명 | ← | 투명(왜 추천하는지 밝힘) |
| 추천 앨거리듬 | aggregation + 비즈니스 룰 | 상품 연관성 | 개인화되지 않은 요약 및 상품-상품 필터링 |
아마존에는 Improve your recommendations가 있어서 내가 산 상품, 가지고 있는 상품, 평가한 항목, 좋아한 항목, 선물로 표시한 항목 등 다양한 상품별로 평점을 관리할 수 있다. 또한 Betterizer라는 게 있어서 책, 영화, 음악 등을 추천해준다. 또한 Deals에서도 여러 가지 상품을 추천해준다.
아래는 사실 위보다 앞서 진행된 "강의 개요"인데 본 수업 내용을 벗어나거나 어려운 개념도 포함돼 있어서 별도로 빼놓았다. 본 내용을 이해하는 것과 별개로 봐도 될 것 같아서 아래로 뺐다.
강의 개요
추천 시스템의 배경에는 정보 재사용, 보관되는 취향(persistent preference)이 있다.
야구 경기가 끝나면 다른 사람을 따라 출구를 찾아가는 것 같은 social navigation은 사회적 정보 재사용으로 이어진다. 또한 혈거인이 처음 보는 과실을 먹을 때 다른 사람들이 안전하게 먹었는지 의견을 듣는 것은 비평가의 출현으로 이어진다. (하나의 사실에 대해 비평가는 각자 자기 관점에서 의견을 제시한다.)
정보 조회(retrieval)는 수많은 데이터에서 원하는 것을 찾는 것인데 이를 위해 TFIDF(term frequency inverse document frequency) 접근법이 있다. 정보 필터링은 컨텐트 스트림에서 필요한 것을 가려내는 것인데 계속 변화하는 데이터를 인덱싱하는 것보다는 사용자가 원하는 또는 원하지 않는 것을 프로파일링하는 것이 낫다.
수동 협업적(collaborative) 필터링은 사람들의 정보 취향(preference)이 단순한 검색 키워드들로 나타낼 수 없게 복잡한 경우를 전제로 하는 것으로 예를 들어 월드컵 경기에 관심 있더라도 월드컵에 대한 우수한 기사에 더 관심 있는 경우 이것은 키워드로만은 찾아낼 수 없다. 작은 집단이라면 컨텐트와 댓글을 함께 묶어 찾아보게 한 Xerox의 Tapestry, 컨텐트를 관련 독자에게 전달하는 Active CF가 있었다.
자동 협업적 필터링은 미네소타 대학의 GroupLens 프로젝트가 있는데 Nearest-Neighbor 접근법 등이 있었다.
(중략)
MovieLens.org 사이트의 추천 시스템을 보자면,
- 개인들의 평점을 C.F. Engine을 통해 저장. 또한 개인간의 취향이 얼마나 비슷한가를 pair-wise correlation으로 저장함. 비슷하면 1, 반대면 -1, 겹치는 게 없으면 0에 가까운 값임.
- 이제 요청이 들어오면 비슷한 취향의 사람들을 통해 추천, 예측이 가능함
추천 시스템을 만드는 데 있어서 Historical Challenges
- 의견 및 경험 데이터의 수집
- 목적에 관련된 데이터 찾기
- 추천 계산
- 유용한 방식으로의 데이터 표현